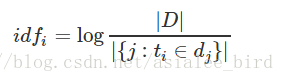其中,|D| 是语料库中的文件总数。 |{j:ti∈dj}| 表示包含词语 ti 的文件数目(即 ni,j≠0 的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{j:ti∈dj}|
即:
(3)TF-IDF实际上是:TF * IDF
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
公式:
注: TF-IDF算法非常容易理解,并且很容易实现,但是其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况。
2、TF-IDF应用
(1)搜索引擎;(2)关键词提取;(3)文本相似性;(4)文本摘要
3、TF-IDF实战具体应用说明

从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。(如果还计算"的"字的TF-IDF,那将是一个极其接近0的值。)所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词。
除了自动提取关键词,TF-IDF算法还可以用于许多别的地方。比如,信息检索时,对于每个文档,都可以分别计算一组搜索词("中国"、"蜜蜂"、"养殖")的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
百度/谷歌SEO总结:
TF-IDF这种算法在谷歌搜索排名应用十分广泛,至于百度,虽然他们不是十分重视,但是在百度官方的培训视频当中,也有工程师对这种算法做了详细讲解,只是起到一定作用,但是发现居然有百度/谷歌SEO培训的站点,居然拿这开始忽悠菜鸟,做收费培训,在这里告诫所有学员,学习SEO排名技术,一定要摆正观念,多看,多学,想要靠别人给你培训学习好快排技术,这种你只有被骗的份,排名是众多知识点的汇总,免费的你都看不懂,学不会,你还想学好,异想天开。
(本文原标题:百度/谷歌seo实战培训_TF-IDF算法排名教学「操作排名」)



 发表于 5-16 11:03
发表于 5-16 11:03